概要
open関数を使用してファイルの読み書きを行う方法について紹介する。
ファイル操作まわりの前提
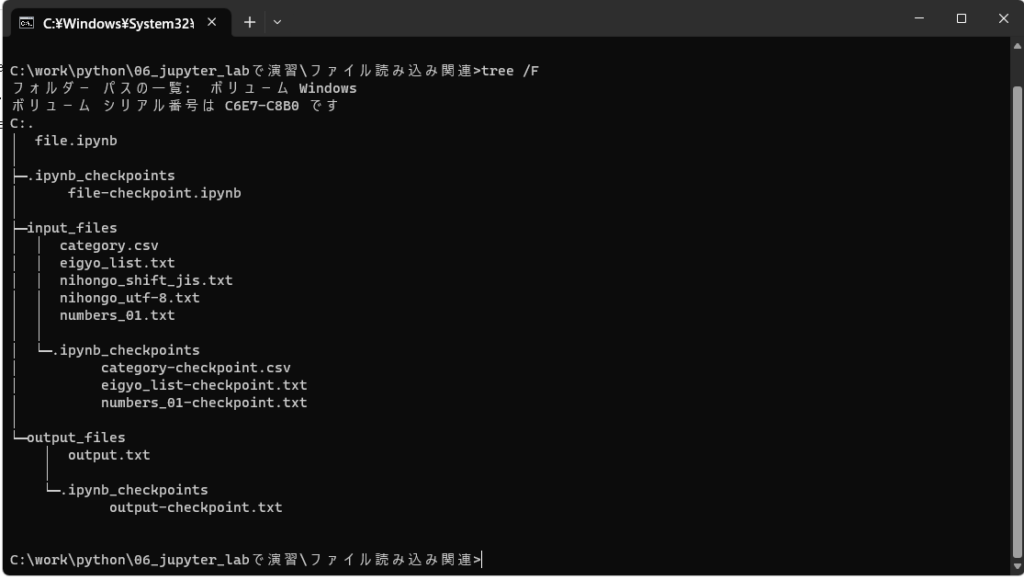
以下のディレクトリ構造でjupyter-labを使用している。
使用方法
処理の流れ
ファイルを読み込む際にも書き込む際にも、以下の流れでプログラミングする。
②ファイル内容の読み込み(または書き込み)
③ファイルを閉じる
open()
ファイルオブジェクトの取得方法は以下の通り。
変数 = open(①ファイルパス, ②モード, ③エンコーディング)
①ファイルパス:ファイルのパス情報を記述
②モード:以下詳細
| モード | 意味 |
|---|---|
| “r” | 既存ファイルを読み込みモードで開く(ファイルが存在しない場合はエラー) ※デフォルト設定 |
| “w” | ファイルを書き込みモードで開く(ファイルを保存する際には上書き) |
| “a” | ファイルを書き込みモードで開く(ファイルを保存する際には追記) |
| “x” | 新規ファイルを書き込みモードで開く(既に存在する場合はエラー) |
③エンコーディング:以下詳細
| 文字コード | 意味 |
|---|---|
| “utf-8” | 最も使用されている文字コード ※デフォルト |
| “shit-jis” | Windows環境で使用される、日本語表記が可能な文字コード |
| “euc_jp” | UNIX環境で使用される、日本語表記が可能な文字コード |
| “iso2022_jp” | 電子モール上で使用される、日本語表記が可能な文字コード |
ファイルを読み込むだけなら②のモードは省略可能(デフォルトで”r”のため)。
また、utf-8で作成されているファイルの場合は③のエンコーディングも同様に省略可能。
(※使用しているプラットフォームによってはデフォルトでutf-8でない場合もあり)
ファイル読み込み
read()
ファイル内容をすべて文字列として取得する。
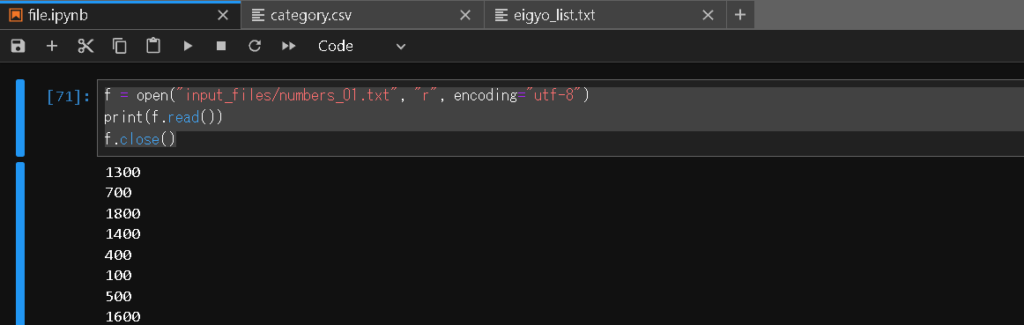
f = open("input_files/numbers_01.txt", "r", encoding="utf-8")
print(f.read())
f.close()
読み込む対象のファイルがutf-8で作成されている場合、以下のように省略可能。
f = open("input_files/numbers_01.txt") # ②モードと③エンコーディングの設定を省略
print(f.read())
f.close()
ファイル内の文字コードとopen関数のエンコーディングに差異がある場合、エラー(UnicodeDecodeError)になるので注意。
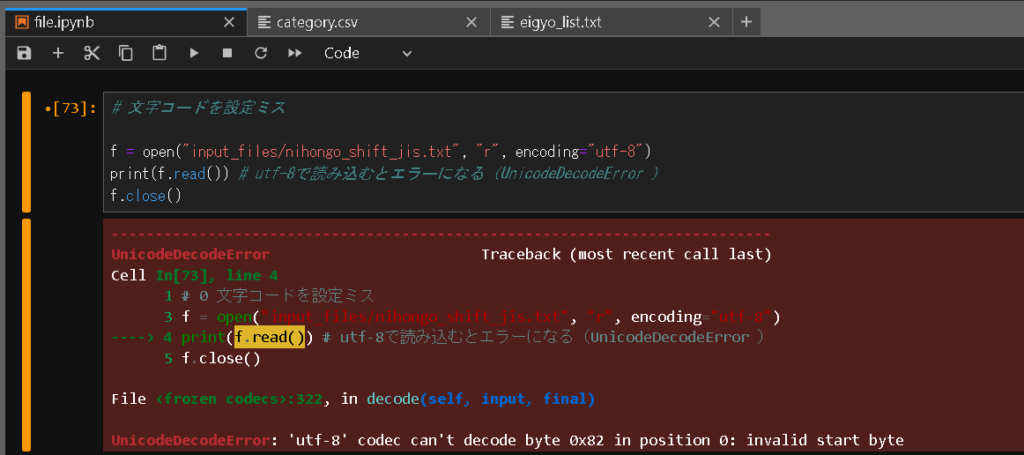
以下はshift-jisで作成されたファイルをutf-8エンコードで開こうとした結果、エラーになるケース。
# 文字コードを設定ミス
f = open("input_files/nihongo_shift_jis.txt", "r", encoding="utf-8")
print(f.read()) # utf-8で読み込むとエラーになる(UnicodeDecodeError )
f.close()
また、ファイルを閉じた後で、再度ファイルオブジェクトの処理を行うとエラーになる。
f = open("input_files/numbers_01.txt")
print(f.read())
f.close() # ファイルを閉じる
print(f.read()) # エラー(ValueError)が発生
readlines()
ファイル内容を一行ずつリストにして取得できる。
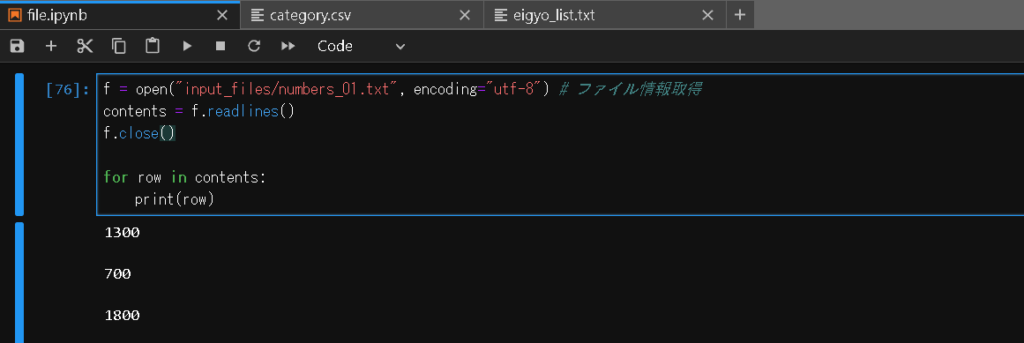
f = open("input_files/numbers_01.txt", encoding="utf-8") # ファイル情報取得
contents = f.readlines() # ファイル情報をリストで取得
f.close()
for row in contents:
print(row) # 一行ずつ表示
with文
with文を使用すると、自動的にファイルを閉じてくれるため、close()メソッドを呼び出す必要がなくなる。
with open(①ファイルパス, ②モード, ③エンコーディング) as ファイル変数:①~③の内容については、open()と同じ。
以下のようにファイルオブジェクトをループさせれば、一行ずつ処理が可能となる。
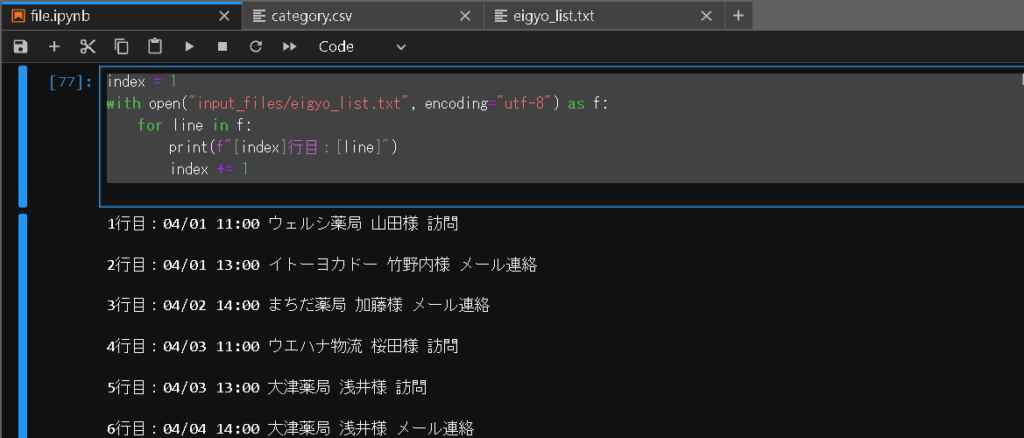
index = 1
with open("input_files/eigyo_list.txt", encoding="utf-8") as f:
for line in f:
print(f"{index}行目:{line}")
index += 1
readlines()もリストとしてファイル内容を取得できるが、一度にすべてを取得するため処理が遅くなったりする。
そのため、for文でファイルオブジェクトをループして一行ずつ参照する処理の方がメモリ効率が良い。
末尾の改行を削除
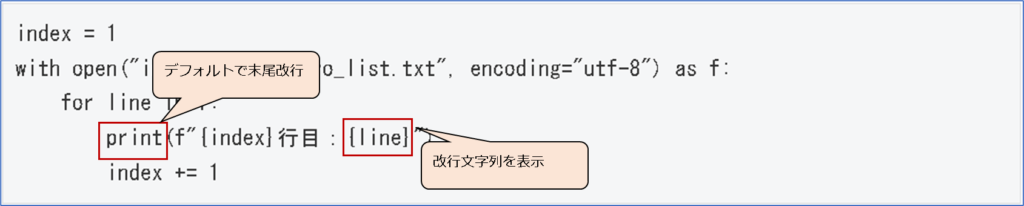
ファイルオブジェクトをループして表示させると、無駄な空行が表示されている。
これはファイル内に改行が存在する場合、改行文字列(\n)を取得しているため。
以下のように文字列に\nが存在すると、改行される。
print("改行文字\nが入ると\n改行される")
# 出力
#改行文字
#が入ると
#改行される
空行が表示されるのは以下のような構造となっているため。
空行を削除するためにはいくつか方法があるが、今回は文末の空白や改行文字列を削除するrstrip()を使用する。
index = 1
with open("input_files/eigyo_list.txt", encoding="utf-8") as f:
for line in f:
row = line.rstrip()
print(f"{index}行目:{row}")
index += 1
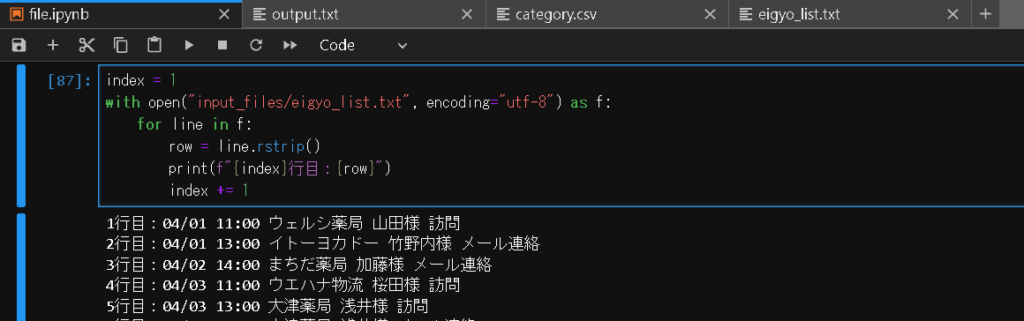
上記はline.rstrip()とすることで文末の改行文字列を削除している。
ファイル書き込み
write()
ファイルを書き込む際には、書き込みモード(”w”)でファイルオブジェクトを取得した後、
write()メソッドを使用してファイルに書き込む。
with open("output_files/output.txt", "w", encoding="utf-8") as f:
f.write("Hello")
f.write(" World")
f.write("\n改行させたいときは\n改行文字をいれる")

write()を使用する際に、改行を挿入したい場合は\nを入れないと上記のように改行されないので注意。
また、書き込んだ後に、以下のように再度同じ”w”モードで書き込むと上書きされる。
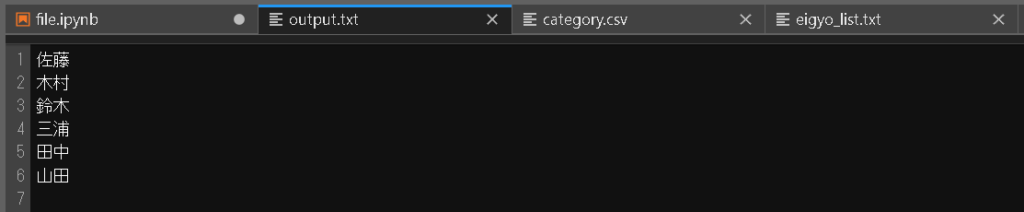
import os
names = ["佐藤", "木村", "鈴木", "三浦"]
with open("output_files/output.txt", "w", encoding="utf-8") as f:
for name in names:
f.write(f"{name}\n")

続けてファイルの末尾に書き込みたい場合は、追記(”a”)モードでファイルオブジェクトを操作する。
names = ["田中", "山田"]
with open("output_files/output.txt", "a", encoding="utf-8") as f:
for name in names:
f.write(f"{name}\n")